从文本文件中编译职位名称的Python正则表达式
我有一个文本文件,里面的内容是这样的,每一列之间用制表符(Tab)分隔:
CAMPUS NAME TITLE
AUJV "Judith" Research Technician Associate
BRGE "Aagesen" ADJUNCT CLINICAL INSTRUCTOR
YJFF "Matthew" HOUSE OFFICER IV
我想写一个正则表达式,来找到第三列的字符,也就是第二个制表符后面的内容,并把它们标记为“jobtitle”。这样做的目的是为了把职位名称归在一起,以便我可以按出现频率对它们进行排序。
这是我目前的进展,但我觉得我匹配到的字符不对:
jobtitle_re = re.compile(r"[^\t\w\t]+,(?P<jobtitle>\w+)", re.I)
我代码的其余部分是这样的:
for line in salary_file.readlines():
line.rstrip()
(campus, name, title) = line.split('\t')
jobtitle = jobtitle_re.match(title).group('jobtitle')
titlecount[jobtitle] = titlecount.setdedault(jobtitle,0)+1
print "\nMost common job titles\n-------"
i = 0
for title, titlecount in sorted(titlecount.iteritems(), key=lambda (k,v): (v,k), reverse=True):
i += 1
print "%d. %s\t%s" % (i,title, titlecount)
2 个回答
0
我不明白为什么你觉得split不适用,但这里有一个正则表达式作为替代方案:
^[A-Z]+[ \t]+"\w+"[ \t]+(?P<jobtitle>[\w ]+)$
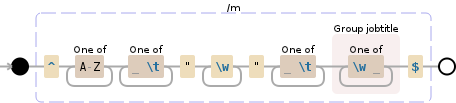
注意,如果数据确实是用制表符分隔的,你可以把 [ \t]+ 改成 \t+
0
我也不明白你为什么需要正则表达式。这样做怎么样...
from collections import Counter
titles = []
for line in salary_file.readlines():
line.rstrip()
(campus, name, title) = line.split('\t')
titles.append(title)
print "\nMost common job titles\n-------"
for i, (title, titlecount) in enumerate(Counter(titles).most_common()):
print "%d. %s\t%s" % (i, title, titlecount)