为什么python中的map.pool会卡住?
我有一个命令行程序,运行时需要输入一些文本作为参数:
somecommand.exe < someparameters_tin.txt
这个程序运行的时间比较长,通常需要半小时到几个小时,然后会生成一些文本文件作为结果。我想写一个脚本,让多个这样的程序同时运行,充分利用多核机器的所有核心。在其他操作系统上,我会使用“fork”来实现,但在很多Windows的脚本语言中并没有这个功能。我觉得Python的多进程功能可能可以解决这个问题,所以我想试试,虽然我对Python一点都不懂。我希望有人能告诉我我哪里做错了。
我写了一个脚本(见下文),它会指向一个目录,找到可执行文件和输入文件,然后使用pool.map和一个进程池来启动它们,并用call函数来调用。开始的时候(当我启动第一批n个进程时)看起来还不错,n个核心的使用率是100%。但是后来我发现这些进程变得闲置,CPU的使用率几乎没有,或者只有几%。虽然始终有n个进程在运行,但它们的工作效率很低。这个情况似乎发生在它们要写输出数据文件的时候,一旦开始写,就会导致整个系统变得缓慢,核心的利用率在几%到偶尔的50-60%之间波动,但从来没有接近100%。
如果我能附上图(编辑:现在我不能,至少暂时不能),这里有一个进程运行时间的图。下方的曲线是我手动打开n个命令提示符,并保持n个进程同时运行时的情况,轻松让电脑的使用率接近100%。(这条线是规律的,慢慢从接近0增加到0.7小时,涉及32个不同的进程,参数各不相同。)上方的线是这个脚本某个版本的结果——运行时间平均增加了大约0.2小时,而且变得不那么可预测,就像我把下方的线加上了0.2和一个随机数。
这是图的链接: 运行时间图
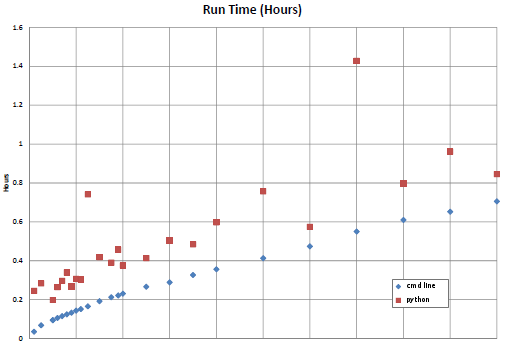{kind=link}
编辑:现在我想我可以添加这个图了。

我哪里做错了?
from multiprocessing import Pool, cpu_count, Lock
from subprocess import call
import glob, time, os, shlex, sys
import random
def launchCmd(s):
mypid = os.getpid()
try:
retcode = call(s, shell=True)
if retcode < 0:
print >>sys.stderr, "Child was terminated by signal", -retcode
else:
print >>sys.stderr, "Child returned", retcode
except OSError, e:
print >>sys.stderr, "Execution failed:", e
if __name__ == '__main__':
# ******************************************************************
# change this to the path you have the executable and input files in
mypath = 'E:\\foo\\test\\'
# ******************************************************************
startpath = os.getcwd()
os.chdir(mypath)
# find list of input files
flist = glob.glob('*_tin.txt')
elist = glob.glob('*.exe')
# this will not act as expected if there's more than one .exe file in that directory!
ex = elist[0] + ' < '
print
print 'START'
print 'Path: ', mypath
print 'Using the executable: ', ex
nin = len(flist)
print 'Found ',nin,' input files.'
print '-----'
clist = [ex + s for s in flist]
cores = cpu_count()
print 'CPU count ', cores
print '-----'
# ******************************************************
# change this to the number of processes you want to run
nproc = cores -1
# ******************************************************
pool = Pool(processes=nproc, maxtasksperchild=1) # start nproc worker processes
# mychunk = int(nin/nproc) # this didn't help
# list.reverse(clist) # neither did this, or randomizing the list
pool.map(launchCmd, clist) # launch processes
os.chdir(startpath) # return to original working directory
print 'Done'
2 个回答
我觉得我明白这个意思。当你调用 map 的时候,它会把任务列表分成一小块一小块的,分给每个处理器。默认情况下,这些小块的大小是足够大的,可以把一块分给每个处理器。这是基于一个假设:所有的任务完成所需的时间差不多。
在你的情况下,假设这些任务完成所需的时间差别很大。所以有些工作者比其他人完成得快,这样那些处理器就会闲着。如果是这样的话,那么下面的代码应该能按预期工作:
pool.map(launchCmd, clist, chunksize=1)
虽然效率会低一些,但这应该意味着每个工作者在完成任务后会得到更多的任务,直到所有任务都完成。
有没有可能这些进程在尝试写入一个共同的文件?在Linux系统下,这种情况可能不会出问题,虽然会覆盖数据,但不会导致速度变慢;而在Windows系统下,一个进程可能会获取到这个文件,而其他进程则会因为等待文件变得可用而卡住。
如果你把实际的任务列表换成一些简单的任务,这些任务会使用CPU但不写入磁盘,问题还会出现吗?比如,你可以让任务计算某个大文件的md5值;一旦文件被缓存,其他任务就只会占用CPU,然后输出一行结果到标准输出。或者计算一些复杂的函数之类的。