在Python中用一个列表查找另一个列表的值
我想找一个列表中的子列表。也就是说,如果列表list1,比如说是[1,5],出现在列表list2,比如说是[1,4,3,5,6]中,那就应该返回True。我现在有的代码是这样的:
for nums in l1:
if nums in l2:
return True
else:
return False
这样的话会返回True,但我想要的是只有当list1在list2中按顺序出现时才返回True。所以如果list2是[5,2,3,4,1],它就应该返回False。我在想用比较list1的索引值来实现这个功能,但我不太确定该怎么做。
7 个回答
我觉得这个解决方案是最快的,因为它只遍历了一次,虽然是在较长的列表上,但如果找到匹配项就会提前退出,不会继续遍历下去。(编辑:不过,它没有Alex最新的解决方案那么简洁或快速)
def ck(l1,l2):
i,j = 0,len(l1)
for e in l2:
if e == l1[i]:
i += 1
if i == j:
return True
return False
Anurag Uniyal提出了一个改进方案(见评论),并在下面的对比中有所体现。
这里有一些关于不同列表大小比例的速度测试结果(列表l1是一个包含10个随机值(范围1-10)的列表。列表l2的长度从10到1000不等(同样包含1-10之间的随机值)。
比较运行时间并绘制结果的代码:
import random
import os
import pylab
import timeit
def paul(l1,l2):
i = 0
j = len(l1)
try:
for e in l2:
if e == l1[i]:
i += 1
except IndexError: # thanks Anurag
return True
return False
def jed(list1, list2):
try:
for num in list1:
list2 = list2[list2.index(num):]
except: return False
else: return True
def alex(L1,L2): # wow!
i2 = iter(L2)
return all(lookfor in i2 for lookfor in L1)
from itertools import dropwhile
from operator import ne
from functools import partial
def thc4k_andrea(l1, l2):
it = iter(l2)
try:
for e in l1:
dropwhile(partial(ne, e), it).next()
return True
except StopIteration:
return False
ct = 100
ss = range(10,1000,100)
nms = 'paul alex jed thc4k_andrea'.split()
ls = dict.fromkeys(nms)
for nm in nms:
ls[nm] = []
setup = 'import test_sublist as x'
for s in ss:
l1 = [random.randint(1,10) for i in range(10)]
l2 = [random.randint(1,10) for i in range(s)]
for nm in nms:
stmt = 'x.'+nm+'(%s,%s)'%(str(l1),str(l2))
t = timeit.Timer(setup=setup, stmt=stmt).timeit(ct)
ls[nm].append( t )
pylab.clf()
for nm in nms:
print len(ss), len(ls[nm])
pylab.plot(ss,ls[nm],label=nm)
pylab.legend(loc=0)
pylab.xlabel('length of l2')
pylab.ylabel('time')
pylab.savefig('cmp_lsts.png')
os.startfile('cmp_lsts.png')
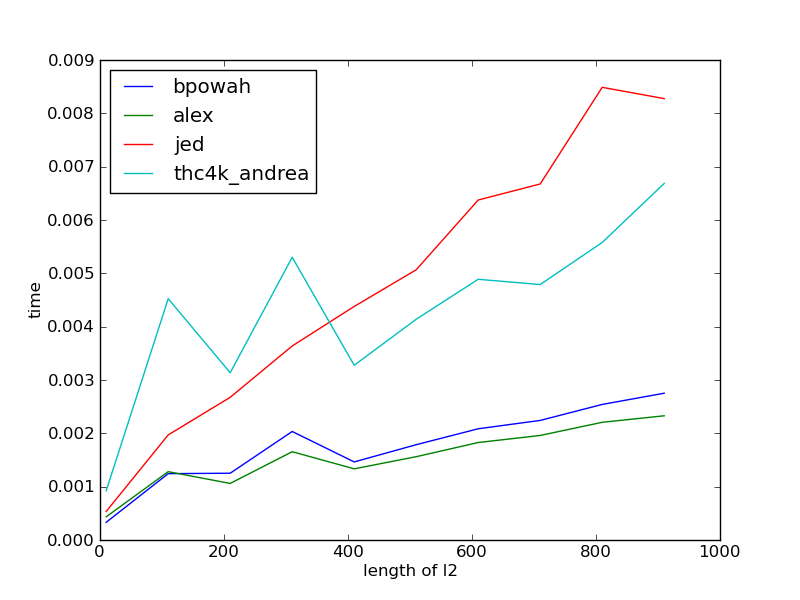
结果:
这个问题看起来有点像作业,所以我想花点时间讨论一下代码片段可能出错的地方。
虽然你在 nums 变量中使用了复数形式的单词,但你需要明白的是,Python 会一次只用这个变量存储 l1 中的一个项目,并在这个“for 循环”中针对每个不同的项目执行代码块一次。
因此,你当前代码片段的结果是,在第一次循环时就会退出,返回 True 或 False,这取决于列表中的第一个项目是否恰好匹配。
编辑: 是的,A1,正如你所说的:逻辑在第一次循环后返回 True。这是因为当 nums 在 l2 中找到时会执行“return”。
如果在“找到”的情况下什么都不做,逻辑会继续执行代码块中的其他逻辑(这里没有),然后开始下一次循环。因此,只有在 l1 中的某个项目在 l2 中没有找到时,它才会返回“False”(确实是在第一次没有找到的情况下)。所以你的逻辑几乎是正确的(如果在“找到”的情况下什么都不做),唯一缺少的就是在 for 循环结束后返回“True”,系统性地返回(因为如果在循环中没有返回 False,那么 l2 中的所有项目都在 l1 中……)。
有两种方法可以修改代码,使其在“找到”的情况下什么都不做。
- 使用 pass,这是一种方便的方式来指示 Python 什么都不做;
“pass”通常用于需要某种动作但我们不想执行任何操作的情况,也可以用于调试等。
- 也可以将测试重写为“not in”。
if nums not in l2:
return False
#no else:, i.e. do nothing at all if found
现在……深入细节。
你的程序可能存在一个缺陷(在建议的更改下),那就是它会认为 l1 是 l2 的子列表,即使 l1 中有两个值为 5 的项目,而 l2 中只有一个这样的值。我不确定这种考虑是否是问题的一部分(可能理解为两个列表都是“集合”,没有重复项目)。但是如果允许重复项,你就需要稍微复杂化逻辑(一个可能的方法是最初复制 l2,每次在 l2 复制中找到“nums”时,删除这个项目)。
另一个考虑是,可能只有当一个列表中的项目按与另一个列表中项目相同的顺序找到时,才能说它是一个子列表……这又取决于问题的定义方式……顺便提一下,一些提出的解决方案,比如 Alex Martelli 的,之所以以这种方式编写,是因为它们以考虑项目顺序的方式解决了问题。
try:
last_found = -1
for num in L1:
last_found = L2.index(num, last_found + 1)
return True
except ValueError:
return False
列表 L2 的 index 方法可以找到第一个参数(num)在列表中的位置。如果你像这里这样传入第二个参数,它会从那个位置开始查找。如果 index 找不到想要的东西,它会抛出一个 ValueError 异常。
所以,这段代码的做法是依次在列表 L2 中查找每个 L1 中的项目 num。第一次查找时从位置 0 开始;之后每次查找时,从上一个找到的项目的下一个位置开始,也就是 last_found + 1(所以一开始我们需要把 last_found 设置为 -1,这样第一次查找时就能从位置 0 开始)。
如果 L1 中的每个项目都能这样找到(也就是说,它在上一个项目找到的位置之后的 L2 中被找到),那么这两个列表就符合条件,代码会返回 True。如果 L1 中的任何一个项目没有找到,代码会捕获到 ValueError 异常,并返回 False。
另一种方法是使用对两个列表的 迭代器,可以通过 iter 这个内置函数来创建。你可以通过调用内置的 next 来“推进”迭代器;如果没有“下一个项目”,也就是迭代器已经用完了,它会抛出 StopIteration。你也可以在迭代器上使用 for 循环,这样会更顺畅一些,适用时可以使用。使用 iter/next 的低级方法:
i1 = iter(L1)
i2 = iter(L2)
while True:
try:
lookfor = next(i1)
except StopIteration:
# no more items to look for == all good!
return True
while True:
try:
maybe = next(i2)
except StopIteration:
# item lookfor never matched == nope!
return False
if maybe == lookfor:
break
或者,稍微高级一点:
i1 = iter(L1)
i2 = iter(L2)
for lookfor in i1:
for maybe in i2:
if maybe == lookfor:
break
else:
# item lookfor never matched == nope!
return False
# no more items to look for == all good!
return True
实际上,这里唯一重要的使用 iter 是为了获取 i2——将内层循环写成 for maybe in i2 可以确保内层循环不会每次都从头开始查找,而是继续上次停止的地方。外层循环也可以用 for lookfor in L1:,因为它没有“重启”的问题。
这里的关键是循环的 else: 子句,它只有在循环没有被 break 中断,而是自然退出时才会触发。
进一步思考这个想法,我们再次想到了 in 操作符,它也可以通过使用迭代器来继续上次停止的地方。大大简化:
i2 = iter(L2)
for lookfor in L1:
if lookfor not in i2:
return False
# no more items to look for == all good!
return True
但现在我们意识到,这正是短路的 any 和 all 内置“短路累加器”函数所抽象出的模式,所以……:
i2 = iter(L2)
return all(lookfor in i2 for lookfor in L1)
我认为这就是你能做到的最简单的方式。唯一剩下的非基础部分是:你需要明确使用一次 iter(L2),以确保 in 操作符(本质上是一个内循环)不会从头开始查找,而是每次都从上次停止的地方继续。