s3asatastore是一个位于botocore和boto3之上的库,它将S3用作keyvalue数据存储而不是实际的数据存储
s3-as-a-service的Python项目详细描述
S3-as-a-datastore是一个位于botocore和boto3之上的库,它将S3用作键值数据存储而不是实际的数据存储
免责声明:这不是一个真正的数据存储,只是一个错觉。如果您有远程高I/O,这不是适合您的库。在
动机
与Memcache或RDS相比,S3确实便宜。在
例如,这是RDS的成本
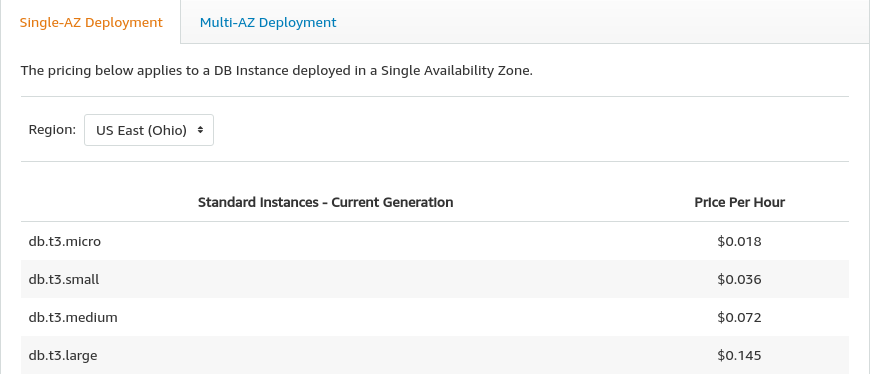
这是S3成本
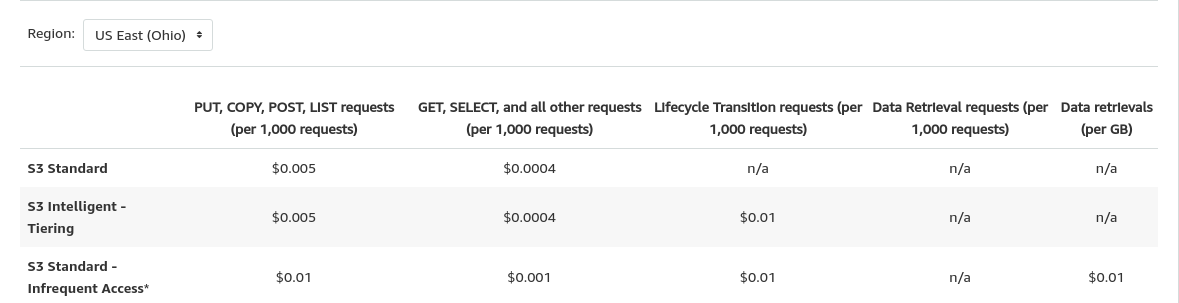
如果一个服务没有很多流量,那么保持RDS部署是浪费,因为它处于空闲状态,但会产生成本。S3没有这个问题。对于具有低读/写操作的服务,或者只有没有U的CRD(如果您不知道这意味着什么,请读CRUD),在S3中保存内容也会得到类似的结果。只要数据没有升级,只有读写,S3就可以使用。不过,如果你不习惯于写很多文档的话。这个库是一个与S3通信的接口,类似于一种伪ORM方式。在
安装
pip3 install s3aads
想法
其主要思想是将数据库映射到一个bucket,表是s3的顶层“文件夹”。其余的嵌套“文件夹”是列。因为bucket在S3中的工作方式,它们对于所有S3 bucket必须是唯一的。这也意味着键的组合必须是唯一的
注意:“folder”周围有引号,因为S3存储桶中的文件是平面的,实际上并没有文件夹。在
示例
^{pr2}$映射到
joeyism-test/daily-data/1/2020/01/01 -> ["a", "b"] joeyism-test/daily-data/2/2020/01/01 -> ["c", "d"] joeyism-test/daily-data/3/2020/01/01 -> ["abk20dj3i"]
但可以用
froms3aadsimportTabletable=Table(name="daily-data",database="joeyism-test",columns=["id","year","month","day"])table.select(id=1,year=2020,month="01",day="01")# b'["a", "b"]'table.select(id=2,year=2020,month="01",day="01")# b'["c", "d"]'table.select(id=3,year=2020,month="01",day="01")# b'["abk20dj3i"]'
使用
froms3aadsimportDatabase,Tabledb=Database("joeyism-test")db.create()table=Table(name="daily-data",database=db,columns=["id","year","month","day"])table.insert(id=1,year=2020,month="01",day="01",data=b'["a", "b"]')table.insert(id=2,year=2020,month="01",day="01",data=b'["c", "d"]')table.insert(id=2,year=2020,month="01",day="01",data=b'["abk20dj3i"]')table.select(id=1,year=2020,month="01",day="01")# b'["a", "b"]'table.select(id=2,year=2020,month="01",day="01")# b'["c", "d"]'table.select(id=3,year=2020,month="01",day="01")# b'["abk20dj3i"]'table.delete(id=1,year=2020,month="01",day="01")table.delete(id=2,year=2020,month="01",day="01")table.delete(id=3,year=2020,month="01",day="01")
美国石油学会
数据库
Database(name)
- name:表的名称
属性
tables:该数据库的表列表(S3 Bucket)
方法
create():创建不存在的数据库(s3bucket)
get_table(table_name) -> Table:传入表名并返回表对象
drop_table(table_name):完全删除表
类方法
list_databases():列出所有可用的数据库(S3桶)
表
Table(name,database,columns=[])
- name:表的名称
- database:数据库对象。如果改为传递字符串,它将尝试获取数据库对象
- columns(默认值:[]):表列
属性
keys:该表中所有键的列表。本质上,列出文件夹中所有文件的名称
完整参数方法
以下方法需要传递所有参数才能使其工作。在
delete(**kwargs):如果传递参数,它将删除该行数据
insert(data:bytes, **kwargs):如果传递data的参数和值,它将插入该字节数据行
insert_string(data:string, **kwargs):如果传递data的参数和值,它将插入该行字符串数据
select(**kwargs)-> bytes:如果传递参数,它将选择该行数据并以字节形式返回值
select_string(**kwargs)-> string:如果传递参数,它将选择该行数据并以字符串形式返回值
部分参数方法
以下方法可以处理传入的部分参数。在
query(**kwargs)-> List[Dict[str, str]]:如果传递参数,它将返回表中可用的参数列表
关键方法
delete_by_key(key):如果传递文件的完整密钥/路径,它将删除该行/文件
insert_by_key(key, data: bytes):如果传递文件和数据的完整键/路径(以字节为单位),它将插入包含数据的行/文件
select_by_key(key) -> bytes:如果传递文件的完整键/路径,它将选择该行/文件并返回数据
query_by_key(key="", sort_by=None) -> List[str]:如果您传递完整的或者文件的部分键/路径,它将返回与模式匹配的键列表
- sort_by:可能的值是Key,LastModified,ETag,Size,StorageClass
方法
distinct(columns: List[str]) -> List[Tuple]:如果传递列列表,它将返回基于这些列的不同元组组合的列表
random_key() -> str:返回数据的随机键
random() -> Dict:返回一组参数和随机数据的data
count() -> int:返回表中的对象数
<first_column_name>s() -> List:取第一列的名称,返回唯一值的列表。在
<n_column_name>s() -> List:取第n列的名称,返回唯一值的列表。在
- 例如,具有["id", "name"]列的表将具有方法table.ids(),该方法将返回一个唯一ID列表
- 项目
标签:
欢迎加入QQ群-->: 979659372

