Python中文网 - 问答频道, 解决您学习工作中的Python难题和Bug
Python常见问题
我已经建立了一个简单的CNN单词检测器,当使用1秒的.wav作为输入时,它能够准确地预测给定的单词。作为标准,我使用音频文件的MFCC作为CNN的输入。你知道吗
但是,我的目标是能够将其应用到多个单词的较长音频文件中,并使模型能够预测是否以及何时说出给定的单词。我一直在网上搜索如何最好的方法,但似乎撞到了墙,我真的很抱歉,如果答案可以很容易地找到通过谷歌。你知道吗
我的第一个想法是把音频文件剪成几个1秒长的窗口互相交叉-
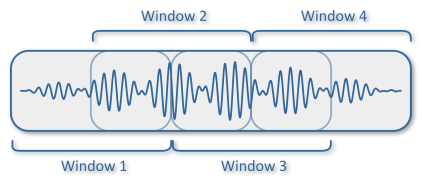
然后将每个窗口转换为MFCC,并将其作为模型预测的输入。你知道吗
我的第二个想法是在尝试分离每个单词时使用起始检测,如果单词是<;1秒,则添加填充,然后将这些作为模型预测的输入。你知道吗
我离这儿远吗?如有任何参考或建议,将不胜感激。非常感谢。你知道吗
Tags: 方法答案模型lt目标标准单词交叉
热门问题
- Python要求我缩进,但当我缩进时,行就不起作用了。我该怎么办?
- Python要求所有东西都加倍
- Python要求效率
- Python要求每1分钟按ENTER键继续计划
- python要求特殊字符编码
- Python要求用户在inpu中输入特定的文本
- python要求用户输入文件名
- Python覆盆子pi GPIO Logi
- Python覆盆子Pi OpenCV和USB摄像头
- Python覆盆子Pi-GPI
- Python覆盖+Op
- Python覆盖3个以上的WAV文件
- Python覆盖Ex中的数据
- Python覆盖obj列表
- python覆盖从offset1到offset2的字节
- python覆盖以前的lin
- Python覆盖列表值
- Python覆盖到错误ord中的文件
- Python覆盖包含当前日期和时间的文件
- Python覆盖复杂性原则
热门文章
- Python覆盖写入文件
- 怎样创建一个 Python 列表?
- Python3 List append()方法使用
- 派森语言
- Python List pop()方法
- Python Django Web典型模块开发实战
- Python input() 函数
- Python3 列表(list) clear()方法
- Python游戏编程入门
- 如何创建一个空的set?
- python如何定义(创建)一个字符串
- Python标准库 [The Python Standard Library by Ex
- Python网络数据爬取及分析从入门到精通(分析篇)
- Python3 for 循环语句
- Python List insert() 方法
- Python 字典(Dictionary) update()方法
- Python编程无师自通 专业程序员的养成
- Python3 List count()方法
- Python 网络爬虫实战 [Web Crawler With Python]
- Python Cookbook(第2版)中文版
将音频切割到分析窗口是一种方法。通常使用一些重叠。可以先计算MFCC特性,然后使用整数帧进行分割,使您最接近所需的窗口长度(1s)。你知道吗
参见How to use a context window to segment a whole log Mel-spectrogram (ensuring the same number of segments for all the audios)?示例代码
相关问题 更多 >
编程相关推荐