Python中文网 - 问答频道, 解决您学习工作中的Python难题和Bug
Python常见问题
我正在探索Pytork,不理解以下示例的输出:
# Initialize x, y and z to values 4, -3 and 5
x = torch.tensor(4., requires_grad = True)
y = torch.tensor(-3., requires_grad = True)
z = torch.tensor(5., requires_grad = True)
# Set q to sum of x and y, set f to product of q with z
q = x + y
f = q * z
# Compute the derivatives
f.backward()
# Print the gradients
print("Gradient of x is: " + str(x.grad))
print("Gradient of y is: " + str(y.grad))
print("Gradient of z is: " + str(z.grad))
输出
Gradient of x is: tensor(5.)
Gradient of y is: tensor(5.)
Gradient of z is: tensor(1.)
我毫不怀疑我的困惑源于一个小小的误解。有人能逐步解释吗
Tags: andofthetotrue示例istorch
热门问题
- Django south migration外键
- Django South migration如何将一个大的迁移分解为几个小的迁移?我怎样才能让南方更聪明?
- Django south schemamigration基耶
- Django South-如何在Django应用程序上重置迁移历史并开始清理
- Django south:“由于目标机器主动拒绝,因此无法建立连接。”
- Django South:从另一个选项卡迁移FK
- Django South:如何与代码库和一个中央数据库的多个安装一起使用?
- Django South:模型更改的计划挂起
- Django south:没有模块名南方人.wsd
- Django south:访问模型的unicode方法
- Django South从Python Cod迁移过来
- Django South从SQLite3模式中删除外键引用。为什么?有问题吗?
- Django South使用auto-upd编辑模型中的字段名称
- Django south在submodu看不到任何田地
- Django south如何添加新的mod
- Django South将null=True字段转换为null=False字段
- Django South数据迁移pre_save()使用模型的
- Django south未应用数据库迁移
- Django South正在为已经填充表的应用程序创建初始迁移
- Django south正在更改ini上的布尔值数据
热门文章
- Python覆盖写入文件
- 怎样创建一个 Python 列表?
- Python3 List append()方法使用
- 派森语言
- Python List pop()方法
- Python Django Web典型模块开发实战
- Python input() 函数
- Python3 列表(list) clear()方法
- Python游戏编程入门
- 如何创建一个空的set?
- python如何定义(创建)一个字符串
- Python标准库 [The Python Standard Library by Ex
- Python网络数据爬取及分析从入门到精通(分析篇)
- Python3 for 循环语句
- Python List insert() 方法
- Python 字典(Dictionary) update()方法
- Python编程无师自通 专业程序员的养成
- Python3 List count()方法
- Python 网络爬虫实战 [Web Crawler With Python]
- Python Cookbook(第2版)中文版
我可以提供一些关于反向传播方面的见解
当操作需要梯度计算的张量(
requires_grad=True)时,PyTorch跟踪反向传播的操作,并构建一个计算图即席让我们看一下您的示例:
其对应的计算图可表示为:
其中
x、y和z称为叶张量。反向传播包括计算x、y和y的梯度,它们分别对应于:dL/dx、dL/dy和dL/dz。其中L是基于图形输出f的标量值。执行的每个操作都需要实现一个反向函数(这是所有数学上可微的PyTorch内置函数的情况)。对于每个操作,该函数有效地用于计算输出w.r.t.输入的梯度向后传球将如下所示:
第一个运算符的
"d(outputs)/d(inputs)"项是:dq/dx = 1和dq/dy = 1。对于第二个运算符,它们是df/dq = z和df/dz = q反向传播归结为应用链规则:
dL/dx = dL/dq * dq/dx = dL/df * df/dq * dq/dx。直观地说,我们分解dL/dx的方式与反向传播的实际方式相反,反向传播需要自下而上进行导航没有形状方面的考虑,我们从^{开始。实际上}和{},我们有{}和{}。你观察到的结果是什么
dL/df的形状是f(参见下面链接的另一个答案)。这导致dL/dx = 1 * z * 1 = z。同样地,对于{我就相关主题给出了一些答案:
Understand PyTorch's graph generation
Meaning of ^{} in PyTorch's ^{}
Backward function of the normalize operator
Difference between ^{} and ^{}
Understanding Jacobian tensors in PyTorch
你只需要了解什么是运算,什么是偏导数,你应该用它们来计算,例如:
将给你
2,因为x*x的导数是2*x如果我们以您的示例为x,我们有:
可修改为:
如果我们在x的函数中取f的偏导数,我们只得到z
在这个结果中,你必须考虑所有其他变量是常数,并应用你已经知道的导数规则。但请记住,Pytork执行以获得这些结果的过程不是符号或数字微分,而是自动微分,这是一种有效获得梯度的计算方法
仔细看看:
https://www.cs.toronto.edu/~rgrosse/courses/csc321_2018/slides/lec10.pdf
我希望您理解,当您执行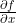
f.backward()时,您在x.grad中得到的是就你而言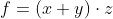 。
因此,简单地说(通过初步计算)
。
因此,简单地说(通过初步计算)
如果您输入x、y和z的值,这就解释了输出
但是,这并不是真正的“反向传播”算法。这只是偏导数(这是你在问题中问的全部问题)
编辑: 如果你想知道它背后的反向传播机制,请参阅@Ivan的答案
相关问题 更多 >
编程相关推荐