Python re.finditer 的 match.groups() 不包含所有匹配组
我正在尝试在Python中使用正则表达式(regex)来查找并打印出多行文本中所有匹配的行。
我搜索的文本可能有以下这种结构:
AAA ABC1 ABC2 ABC3 AAA ABC1 ABC2 ABC3 ABC4 ABC AAA ABC1 AAA
我想从中提取出那些至少出现一次并且前面有AAA的ABC*。
问题是,尽管我能通过分组捕获到我想要的内容:
match = <_sre.SRE_Match object; span=(19, 38), match='AAA\nABC2\nABC3\nABC4\n'>
... 但我只能访问到这个分组的最后一个匹配项:
match groups = ('AAA\n', 'ABC4\n')
下面是我为解决这个问题而使用的示例代码。
#! python
import sys
import re
import os
string = "AAA\nABC1\nABC2\nABC3\nAAA\nABC1\nABC2\nABC3\nABC4\nABC\nAAA\nABC1\nAAA\n"
print(string)
p_MATCHES = []
p_MATCHES.append( (re.compile('(AAA\n)(ABC[0-9]\n){1,}')) ) #
matches = re.finditer(p_MATCHES[0],string)
for match in matches:
strout = ''
gr_iter=0
print("match = "+str(match))
print("match groups = "+str(match.groups()))
for group in match.groups():
gr_iter+=1
sys.stdout.write("TEST GROUP:"+str(gr_iter)+"\t"+group) # test output
if group is not None:
if group != '':
strout+= '"'+group.replace("\n","",1)+'"'+'\n'
sys.stdout.write("\nCOMPLETE RESULT:\n"+strout+"====\n")
2 个回答
你想要找到在一个AAA\n后面紧接着出现的连续ABC\n的模式,并且希望这个匹配方式尽可能贪婪。也就是说,你只想要连续的ABC\n,而不是包含最近的ABC\n的元组。所以在你的正则表达式中,要排除掉子组。
AAA\n(ABC[0-9]\n)+
然后用括号()来捕获你感兴趣的部分,同时记得要排除子组。
AAA\n((?:ABC[0-9]\n)+)
接下来,你可以使用findall()或者finditer()。我觉得finditer更简单,特别是当你需要捕获多个部分的时候。finditer的用法是:
import re
matches_iter = re.finditer(r'AAA\n((?:ABC[0-9]\n)+)', string)
[print(i.group(1)) for i in matches_iter]
findall使用了原来的{1,},因为它是+的更详细的写法:
matches_all = re.findall(r'AAA\n((?:ABC[0-9]\n){1,})', string)
[[print(x) for x in y.split("\n")] for y in matches_all]
这里是你的正则表达式:
(AAA\r\n)(ABC[0-9]\r\n){1,}
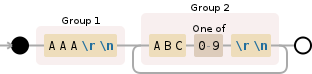
你的目标是捕捉所有紧跟在 AAA 后面的 ABC#。在这个 Debuggex 演示中,你可以看到所有的 ABC# 确实都被匹配到了(它们被高亮显示为黄色)。但是,由于只有“被重复的部分”
ABC[0-9]\r\n
{1,}
没有被捕捉到,这就导致所有匹配项除了最后一个都被丢弃了。为了获取它们,你还必须捕捉到量词:
AAA\r\n((?:ABC[0-9]\r\n){1,})
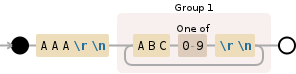
我把“被重复的部分”(ABC[0-9]\r\n)放进了一个非捕捉组里。(我也停止捕捉 AAA,因为你似乎不需要它。)
捕捉到的文本可以按换行符分割,这样就能得到你想要的所有部分。
(注意,单独的 \n 在 Debuggex 中不起作用。它需要\r\n。)
这是一种变通方法。并不是所有的正则表达式都能支持重复捕捉的迭代(哪些可以呢...?)。更常见的方法是循环遍历并处理每个找到的匹配项。这里有一个来自 Java 的例子:
import java.util.regex.*;
public class RepeatingCaptureGroupsDemo {
public static void main(String[] args) {
String input = "I have a cat, but I like my dog better.";
Pattern p = Pattern.compile("(mouse|cat|dog|wolf|bear|human)");
Matcher m = p.matcher(input);
while (m.find()) {
System.out.println(m.group());
}
}
}
输出:
cat
dog
(来自 http://ocpsoft.org/opensource/guide-to-regular-expressions-in-java-part-1/,大约在1/4处)
请考虑将Stack Overflow 正则表达式常见问题解答添加到书签,以便将来参考。这个答案中的链接都来自于此。