正则表达式实现细节
我在回答一个问题时,突然产生了一些疑问:
Python中的正则表达式是怎么实现的?它的效率如何?这个实现是“标准”的,还是会有变化?
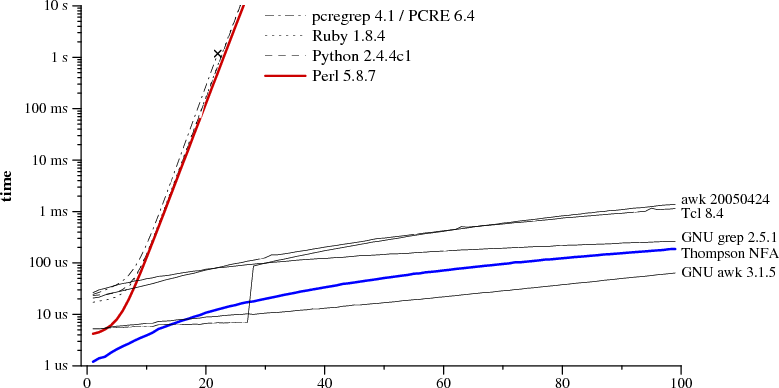
我原本以为正则表达式会用确定性有限自动机(DFA)来实现,所以应该非常高效(最多只需要扫描一次输入字符串)。不过Laurence Gonsalves提到一个有趣的观点,并不是所有Python的正则表达式都是常规的。他举的例子是r"(a+)b\1",这个表达式可以匹配一些a,接着是一个b,然后再是和之前一样数量的a。这个显然不能用DFA来实现。
所以,我想再问一次:Python正则表达式的实现细节和效率保证是什么?
如果有人能解释一下,为什么正则表达式“cat|catdog”和“catdog|cat”在字符串“catdog”中会得到不同的搜索结果,那就更好了。这在我之前提到的问题中也有提到。
3 个回答
使用回溯引用的正则表达式匹配是NP难题,这意味着它的难度至少和NP完全问题一样难。简单来说,这就像是说,这个问题和你可能遇到的任何问题一样复杂,而且大多数计算机科学家认为,在最糟糕的情况下,解决这个问题可能需要非常长的时间,甚至是指数级的时间。如果你能在多项式时间内匹配这样的“正则”表达式(其实从技术上讲,它们并不算正则),你就能赢得一百万美元。
在Python的正则表达式(RE)方面,并没有什么“效率保证”,这和语言的其他部分是一样的。其实,我知道的唯一一个试图建立这种标准的语言是C++的标准库,但即使在C++中,也没有规定说,比如,两个整数相乘必须在固定时间内完成,或者类似的要求;而且也没有保证说会在任何时候应用大的优化。
今天,F. Lundh(他最初负责实现Python当前的正则表达式模块等)在意大利的Pycon大会上提到,他们正在探索的一种方法是将正则表达式直接编译成LLVM中间代码(而不是将其编译成自己的字节码,然后由特定的运行时来解释)。因为普通的Python代码也会被编译成LLVM(在即将发布的Unladen Swallow版本中),这样正则表达式和它周围的Python代码就可以一起进行优化,有时甚至可以进行非常激进的优化。不过,我怀疑这样的东西很快就能达到“生产就绪”的状态;-)