在Python中打开文件并查看其内容
我一直遇到这个错误
runfile('C:/Users/Acer Predator/.spyder-py3/temp.py', wdir='C:/Users/Acer Predator/.spyder-py3') <_io.TextIOWrapper name='C:\Users\Acer Predator\est.txt' mode='r' encoding='cp1252'>
我不知道自己哪里出错了。这是我正在使用的代码:
file = open ("C:\Users\Acer Predator\est.txt", "r")
print(file)
请帮帮我!
我希望输出的内容是文件的内容
2 个回答
0
你光打印文件是看不到里面内容的,得调用读取方法才能把内容打印出来。
file = open(r"C:\temp\tmp\est.txt", "r")
print(file.read())
------------Better way of writing your code------------
with open(r"C:\temp\tmp\est.txt", "r") as file:
print(file.read())
1
根据错误提示,你的“est.txt”文件的编码格式是“cp1252”,所以就按这个格式打开它。
with open('C:\Users\Acer Predator\est.txt', 'r', encoding='cp1252') as file:
content = file.read()
print(content) #
实际上,文件是以不同的编码格式保存的,这些格式取决于不同的操作系统、终端或语言,而cp1252就是其中一种。我们都知道,文件是由字节组成的,而字节就像是一个个小箱子。接下来,我们来看看cp1252到底是什么,下面是一个编码图。
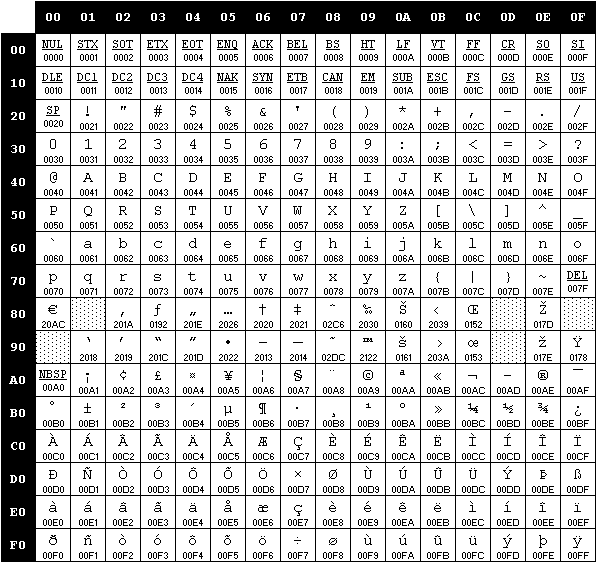
这个编码有点过时了,想了解最新的支持情况,可以查看微软的文档:https://learn.microsoft.com/en-us/powershell/module/microsoft.powershell.management/get-content?view=powershell-7.2
我们以蒙特利尔为例,使用Windows 11、PowerShell和Python 3.14。
octets = b'Montr\xe9al' #iso8859_1
cp1252 = octets.decode('cp1252')
print(cp1252)
#should see:Montréal correct
iso = octets.decode('iso8859_7')
print(iso)
#Montrιal wrong
koi8_r = octets.decode('koi8_r')
print(koi8_r)
#MontrИal wrong
utf_8 = octets.decode('utf-8')
print(utf_8)
#error
new_utf_8 = octets.decode('utf-8', errors='replace')
print(new_utf_8)
#Montr�al no error, but wrong