如何判断网站是否使用了Cookies或基于HTTP的身份验证
我正在尝试通过一个网络服务器自动下载文件。我打算使用wget、curl或者Python的urllib/urllib2。
大多数解决方案都使用wget和urllib以及urllib2。它们都提到了基于HTTP的认证和基于cookie的认证。我的问题是,我不知道存储我数据的网站使用的是哪种认证方式。
以下是我与网站的互动过程:
- 我通常会登录到网站 http://www.anysite.com/index.cgi。
- 我会看到一个登录表单,里面有用户名和密码的输入框。我输入这两个信息后按回车。
- 在整个过程中,网址一直保持为 http://www.anysite.com/index.cgi,但现在我可以看到一系列的文件夹和文件。
- 如果我点击一个文件夹或文件,网址会变成 http://shamrockstructures.com/cgi-bin/index.cgi?page=download&file=%2Fhome%2Fjanysite%2Fpublic_html%2Fuser_data%2Fuserareas%2Ffile.tar.bz2。
然后浏览器会给我一个保存文件的选项。
我想知道如何判断这个网站是使用HTTP认证还是cookie认证。之后我想我可以在Python中使用cookielib或urllib2来连接这个网站,获取文件和文件夹的列表,并在保持连接的情况下递归下载所有内容。
补充说明:我尝试过用wget连接,像这样:wget --http-user "uname" --http-password "passwd" http://www.anysite.com/index.cgi,但它们只返回了登录表单给我。
3 个回答
你可以这样使用pycurl:
import pycurl
COOKIE_JAR = 'cookiejar' # file to store the cookies
LOGIN_URL = 'http://www.yoursite.com/login.cgi'
USER_FIELD = 'user' # Name of the element in the HTML form
USER = 'joe'
PASSWD_FIELD = 'passwd' # Name of the element in the HTML form
PASSWD = 'MySecretPassword'
def read(html):
"""Read the body of the response, with posible
future html parsing and re-requesting"""
print html
com = pycurl.Curl()
com.setopt(pycurl.WRITEFUNCTION, read)
com.setopt(pycurl.COOKIEJAR, COOKIE_JAR)
com.setopt(pycurl.FOLLOWLOCATION, 1) # follow redirects
com.setopt(pycurl.POST, 1)
com.setopt(pycurl.POSTFIELDS, '%s=%s;%s=%s'%(USER_FIELD, USER,
PASSWD_FIELD, PASSWD))
com.setopt(pycurl.URL, LOGIN_URL )
com.perform()
直接使用pycurl可能看起来很“原始”(因为它的设置方法比较简单),但它能完成任务,而且在处理带有cookie的情况时,使用cookie罐的选项也做得不错。
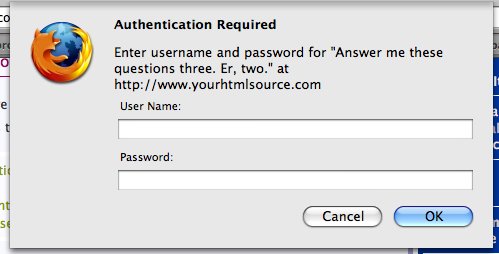
如果你通过网页登录,网站很可能是在用基于cookie的认证方式。虽然技术上也可以用HTTP基本认证,把你的用户名和密码放在网址里,但这样做在大多数情况下是很傻的。如果你看到一个单独的小对话框,里面有用户名和密码的输入框(像这样),那就是在用HTTP基本认证。
{kind=link}
如果你尝试用HTTP基本认证登录,但却又回到了登录页面,就像你现在遇到的情况,这说明这个网站并没有使用HTTP基本认证。
现在大多数网站都使用基于cookie的认证。要用像urllib2这样的HTTP客户端实现这个,你需要发送一个HTTP POST请求,把登录表单里的信息发过去。(有时候你可能需要先请求一下登录表单,因为网站可能会给你一个cookie,而你需要这个cookie才能登录,但通常情况下这不是必须的。)如果成功,这个请求会返回一个“登录成功”的页面,你可以用来测试一下。记得保存从这个请求中得到的cookie。下次请求的时候,要把这些cookie一起发送。每次你发请求,可能会收到新的cookie,你需要把这些也保存下来,并在下次请求时一起发送。
urllib2有一个叫“cookie jar”的功能,它会自动帮你处理这些cookie,当你发送请求和接收网页时,这正是你需要的功能。