特定应用的贝叶斯网络的Pythonic实现
我问这个问题的原因: 去年我写了一些C++代码,用来计算某种模型的后验概率(这个模型是通过贝叶斯网络描述的)。这个模型效果不错,后来有其他人开始使用我的软件。现在我想改进我的模型。因为我正在为新模型编写一些稍微不同的推理算法,所以我决定使用Python,因为运行速度不是特别重要,而Python可能让我写出更优雅、更易管理的代码。
通常在这种情况下,我会在Python中寻找现有的贝叶斯网络包,但我使用的推理算法是我自己写的,我还觉得这是一个很好的机会来学习更多关于Python设计的知识。
我已经找到一个很棒的Python模块,用于网络图(networkx),它允许你给每个节点和每条边附加一个字典。简单来说,这让我可以给节点和边添加属性。
对于特定的网络及其观察数据,我需要写一个函数来计算模型中未分配变量的可能性。
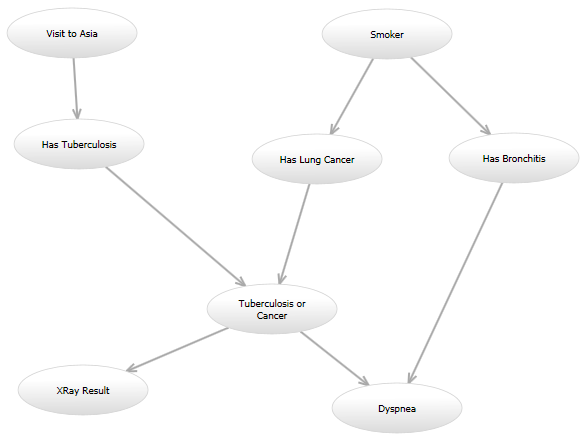
举个例子,在经典的“亚洲”网络中(http://www.bayesserver.com/Resources/Images/AsiaNetwork.png),已知“X光结果”和“呼吸困难”的状态,我需要写一个函数来计算其他变量在某些值下的可能性(根据某个模型)。
{kind=link}
这是我的编程问题: 我打算尝试几种模型,将来可能还会想尝试其他模型。例如,一个模型可能看起来和亚洲网络完全一样。在另一个模型中,可能会从“访问亚洲”到“有肺癌”添加一条有向边。还有一个模型可能使用原始的有向图,但“呼吸困难”节点在“结核或癌症”和“有支气管炎”节点已知状态下的概率模型可能会不同。所有这些模型计算可能性的方式都会不同。
所有模型之间会有很大的重叠;例如,多个边连接到一个“或”节点时,如果所有输入都是“0”,结果总是“0”,否则就是“1”。但有些模型的节点会取某个范围内的整数值,而其他模型则是布尔值。
过去我在编写这样的程序时遇到过困难。我不想隐瞒,确实有不少代码是复制粘贴的,有时我需要在多个文件中传播单个方法的更改。这次我真的想花时间把事情做好。
一些选项:
- 我已经在正确的方向上了。先写代码,之后再问问题。复制粘贴代码并为每个模型创建一个类更快。这个世界是个黑暗而无序的地方……
- 每个模型都是自己的类,但也是一个通用贝叶斯网络模型的子类。这个通用模型将使用一些将被重写的函数。Stroustrup会为此感到骄傲。
- 在同一个类中创建几个函数来计算不同的可能性。
- 编写一个通用的贝叶斯网络库,并将我的推理问题作为这个库读取的特定图形实现。节点和边应该被赋予像“布尔值”和“或函数”这样的属性,这些属性可以在已知父节点状态的情况下,用来计算不同结果的概率。这些属性字符串,比如“或函数”,甚至可以用来查找并调用正确的函数。也许几年后我会做出类似1988年版本的Mathematica的东西!
非常感谢你的帮助。
更新: 面向对象的思想在这里很有帮助(每个节点都有一组指定的前驱节点,每个节点都有一个可能性函数,用于计算在前驱节点状态已知的情况下其不同结果状态的可能性,等等)。面向对象编程万岁!
4 个回答
我对贝叶斯网络不是很熟悉,所以希望下面的内容对你有帮助:
以前我遇到过一个看起来类似的问题,是关于高斯过程回归器,而不是贝叶斯分类器。
我最后使用了继承,这个方法效果很好。所有与模型相关的参数都是通过构造函数来设置的。calculate()函数是虚拟的。
这样做的好处是,可以很方便地组合不同的方法,比如有一个求和的方法,可以把任意数量的其他方法结合在一起,这样也能很好地工作。
Mozart/Oz3约束推理系统解决了一个类似的问题:你可以用有限范围变量的约束、约束传播器和分配器、成本函数来描述你的问题。当没有更多推理可以进行,但仍然有未绑定的变量时,它会利用你的成本函数来划分问题空间,选择最有可能降低搜索成本的未绑定变量。比如,如果X在[a,c]之间,而c(a < b < c)是最有可能降低搜索成本的点,那么你就会得到两个问题实例:一个是X在[a,b]之间,另一个是X在[b,c]之间。Mozart在这方面做得相当优雅,因为它把变量绑定作为一种重要的对象来处理(这非常有用,因为Mozart在并发和分布式环境中广泛应用,可以将问题空间移动到不同的节点)。在它的实现中,我猜它使用了一种写时复制的策略。
你当然可以在基于图的库中实现写时复制的方案(小提示:numpy使用各种策略来减少复制;如果你基于它来构建图的表示,可能会免费获得写时复制的语义),从而达到你的目标。
我在业余时间一直在做这方面的工作,已经有一段时间了。我现在大概是第三或第四个版本了。其实我正在准备发布Fathom的另一个版本(https://github.com/davidrichards/fathom/wiki),这次会加入动态贝叶斯模型和不同的数据存储方式。
为了让我的回答更清晰,内容变得有点长,抱歉。下面是我解决这个问题的方法,这似乎能间接回答你的一些问题:
我从Judea Pearl对贝叶斯网络中信念传播的分析开始。简单来说,这就是一个图,父节点提供先验赔率(因果支持),而子节点提供可能性(诊断支持)。这样,基本的类就是一个BeliefNode,类似于你描述的,在BeliefNodes之间多了一个LinkMatrix。通过这种方式,我可以通过使用的LinkMatrix类型来明确选择我使用的可能性类型。这不仅让后续解释信念网络的工作变得简单,也使计算过程更简单。
我对基本的BeliefNode进行的任何子类化或修改,都是为了处理连续变量,而不是改变传播规则或节点关联。
我决定将所有数据保存在BeliefNode内部,只有固定数据放在LinkedMatrix中。这是为了确保我能保持干净的信念更新,尽量减少网络活动。这意味着我的BeliefNode存储:
- 一个子节点引用的数组,以及来自每个子节点的过滤后可能性和为该子节点进行过滤的链接矩阵
- 一个父节点引用的数组,以及来自每个父节点的过滤后先验赔率和为该父节点进行过滤的链接矩阵
- 该节点的综合可能性
- 该节点的综合先验赔率
- 计算出的信念,或后验概率
- 一个有序的属性列表,所有先验赔率和可能性都遵循这个列表
LinkMatrix可以用多种不同的算法构建,这取决于节点之间关系的性质。你描述的所有模型实际上只是不同的类。最简单的做法是默认使用或门,然后如果节点之间有特殊关系,再选择其他方式处理LinkMatrix。
我使用MongoDB来存储和缓存数据。我在一个事件模型中访问这些数据,以提高速度和异步访问。这使得网络在性能上相当不错,同时如果需要的话也可以非常庞大。此外,由于我以这种方式使用Mongo,我可以轻松为同一个知识库创建新的上下文。例如,如果我有一个诊断树,某个诊断的诊断支持将来自患者的症状和测试。我所做的是为该患者创建一个上下文,然后根据该患者的证据传播我的信念。同样,如果医生说某个患者可能同时患有两种或更多疾病,我可以改变一些链接矩阵,以不同的方式传播信念更新。
如果你不想使用像Mongo这样的系统,但计划有多个用户在知识库上工作,你需要采用某种缓存系统,以确保你始终在处理最新更新的节点。
我的工作是开源的,如果你愿意可以跟着一起看。我的代码都是Ruby,所以和你的Python有些相似,但不一定能直接替换。我设计中一个我喜欢的地方是,所有人类理解结果所需的信息都可以在节点内部找到,而不是在代码中。这可以通过定性描述或网络结构来实现。
那么,我和你的设计有一些重要的不同:
- 我不在类内部计算可能性模型,而是在节点之间的链接矩阵中计算。这样,我就不会遇到在同一个类中组合多个可能性函数的问题。我也不需要处理一个模型和另一个模型的问题,我可以为同一个知识库使用两个不同的上下文并比较结果。
- 我通过让人类决策变得明显来增加透明度。也就是说,如果我决定在两个节点之间使用默认的或门,我知道我是什么时候添加的,并且这只是一个默认决策。如果我稍后回来更改链接矩阵并重新计算知识库,我会有一个关于我为什么这样做的备注,而不是仅仅是一个选择了某种方法的应用。你可以让你的用户记录这类事情。无论你如何解决这个问题,最好是让分析师逐步对话,解释他们为什么以某种方式设置。
- 我可能会对先验赔率和可能性更加明确。我不太确定这一点,只是看到你使用不同的模型来改变你的可能性数字。如果你的后验信念计算模型不是这样分解的,我所说的很多内容可能完全无关紧要。我有一个好处,就是可以进行三个异步步骤,可以按任意顺序调用:将改变的可能性向上传播,向下传播改变的先验赔率,以及重新计算节点本身的综合信念(后验概率)。
一个大警告:我所谈论的部分内容还没有发布。我一直在处理这些内容,直到今天早上2点,所以这些内容绝对是最新的,并且我会定期关注,但还没有全部公开。由于这是我的热情所在,如果你有任何问题或想一起合作做项目,我很乐意回答。